AI
Tutorial
Education
Comprendre le RAG : la technique qui rend vos chatbots vraiment utiles
Épisode 2 de la série "L'IA sans bullshit" — où on vous explique concrètement ce qui rend un chatbot utile vs inutile.
Le problème : des IA qui racontent n'importe quoi
Vous avez déjà eu cette expérience : vous posez une question à ChatGPT ou à un chatbot d'entreprise, et la réponse semble parfaitement construite, articulée, convaincante… mais complètement fausse.
C'est ce qu'on appelle les hallucinations. Et c'est le problème n°1 des LLMs (Large Language Models) en 2025. Une étude de Vectara (2024) a mesuré que les LLMs les plus populaires hallucinent dans 3 % à 27 % des cas selon le modèle et le type de question — même GPT-4 et Claude 3.5 ne sont pas épargnés.

À gauche : un LLM qui invente. À droite : un LLM RAG qui consulte ses sources avant de répondre.
C'est là qu'intervient le RAG — et c'est probablement la technique la plus importante à comprendre si vous voulez utiliser l'IA de façon fiable.
Qu'est-ce que le RAG, concrètement ?
RAG signifie Retrieval-Augmented Generation — en français : génération augmentée par la récupération. Le concept a été introduit en 2020 par des chercheurs de Facebook AI Research (FAIR) dans un paper fondateur (Lewis et al., 2020).
L'idée est simple mais puissante :
Au lieu de demander à l'IA de répondre "de mémoire"…
…on lui donne accès aux bons documents AVANT qu'elle réponde.
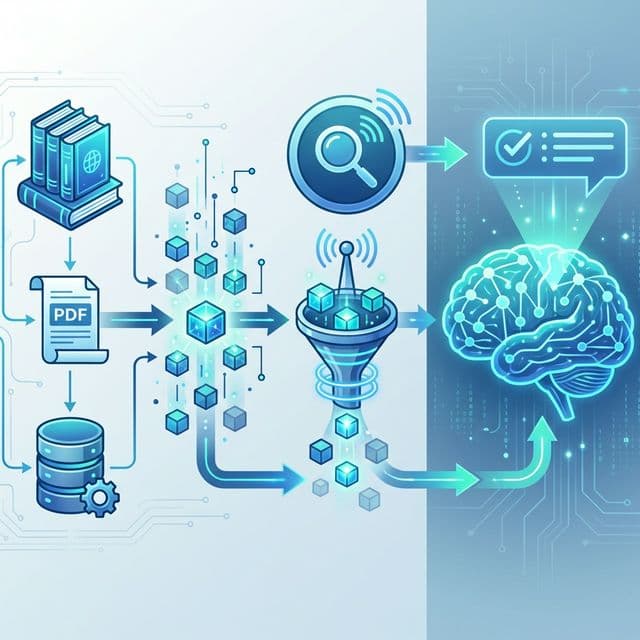
Le pipeline RAG : documents → chunking → embeddings → retrieval → génération augmentée
Les 4 étapes du pipeline RAG
Ingestion : préparer la base de connaissances
Vos documents (PDF, pages web, FAQ, manuels) sont découpés en petits morceaux (chunks) de 200-500 tokens. C'est comme découper une encyclopédie en fiches thématiques.
Chaque chunk est ensuite transformé en un vecteur numérique (embedding) via un modèle spécialisé comme OpenAI text-embedding-3-small ou le modèle open-source BGE-M3 de BAAI.
Stockage : la base vectorielle
Ces vecteurs sont stockés dans une base de données vectorielle (Pinecone, Weaviate, Chroma, pgvector). Chaque vecteur capture le « sens » sémantique du chunk, pas juste les mots.
Concrètement, un vecteur est une liste de 768 à 3072 nombres décimaux qui représente le « sens » du texte dans un espace mathématique multidimensionnel.
Retrieval : trouver les bons passages
Quand l'utilisateur pose une question, celle-ci est aussi convertie en vecteur, puis comparée aux vecteurs de la base pour trouver les chunks les plus proches sémantiquement.
La similarité cosinus est la mesure la plus courante : deux textes qui « parlent de la même chose » auront des vecteurs pointant dans la même direction, même s'ils utilisent des mots différents.
Generation : répondre avec contexte
Les chunks les plus pertinents (3 à 10 en général) sont injectés dans le prompt du LLM avec la consigne : « Réponds UNIQUEMENT en te basant sur ces documents. »
Le LLM devient alors un « rédacteur expert » qui synthétise l'information des documents fournis au lieu d'inventer. Résultat : moins d'hallucinations, des réponses traçables et vérifiables.
Pourquoi le RAG change tout
| Critère | ❌ LLM seul ("vanilla") | ✅ LLM + RAG |
|---|---|---|
| Hallucinations | 3–27 % des réponses (Vectara, 2024) | Réduites de 50-70 % selon les implémentations |
| Sources des réponses | Données d'entraînement statiques (date de cutoff) | Vos documents actualisés en temps réel |
| Traçabilité | Impossible de savoir d'où vient l'info | Chaque réponse cite ses sources exactes |
| Mise à jour | Nécessite un ré-entraînement coûteux ($$$) | Ajoutez/modifiez des documents, c'est instantané |
| Coût | Fine-tuning = $10K–$100K+ | Base vectorielle = $20–500/mois |
| Données privées | Non prises en compte (sauf fine-tuning) | Intégrées naturellement dans la base |
Cas concret : le chatbot SupDeco Dakar
Pour illustrer le RAG en action, voici un projet réel que j'ai développé : un chatbot de service client de simultaion SupDeco Dakar, une grande école de commerce au Sénégal.
Le contexte
L'école recevait des centaines de questions récurrentes chaque mois : conditions d'admission, frais de scolarité, programmes disponibles, dates de rentrée, partenariats internationaux… Les équipes administratives passaient un temps considérable à répondre toujours aux mêmes questions.
La solution RAG
Tous les documents officiels (brochures, FAQ, grilles tarifaires, conventions de partenariat) ont été ingérés et découpés en chunks.
Chaque chunk transformé en embedding et stocké dans une base vectorielle.
Le system prompt du chatbot a été calibré : « Tu es l'assistant officiel de SupDeco Dakar. Réponds UNIQUEMENT à partir des documents fournis. Si l'info n'est pas dans les documents, dis-le clairement. »
Un widget de chat intégré au site web de l'école, accessible 24/7.
Les résultats
~80%
Des questions courantes traitées automatiquement
< 3%
Taux d'hallucination grâce au périmètre documentaire
24/7
Disponibilité vs horaires de bureau limités
Comment implémenter un RAG ? (Guide pratique)
Bonne nouvelle : le RAG est devenu accessible. Voici les principales stacks techniques en 2025 :
| Composant | Options populaires | Coût indicatif |
|---|---|---|
| LLM | GPT-4o, Claude 3.5, Gemini 2.0, Llama 3 (open-source) | $0.01–$0.06 / 1K tokens |
| Modèle d'embedding | OpenAI text-embedding-3-small, BGE-M3, Cohere Embed v3 | $0.00002 / 1K tokens |
| Base vectorielle | Pinecone, Weaviate, Chroma (local), pgvector (PostgreSQL) | Gratuit → $70/mois |
| Framework orchestration | LangChain, LlamaIndex, Haystack | Open-source (gratuit) |
| Interface | Vercel AI SDK, Streamlit, custom React | Gratuit → $20/mois |
Les 5 erreurs à éviter en RAG
❌ Chunks trop grands
✅ Visez 200-500 tokens par chunk. Trop grand = bruit. Trop petit = perte de contexte.
❌ Pas de chevauchement entre chunks
✅ Un overlap de 50-100 tokens entre chunks adjacents préserve les informations aux frontières.
❌ Ignorer les métadonnées
✅ Taguez vos chunks avec source, date, catégorie. Ça permet un filtrage intelligent au retrieval.
❌ Trop ou trop peu de chunks retrieval
✅ 3-5 chunks est un bon point de départ. Trop = confusion pour le LLM. Trop peu = info manquante.
❌ Pas de fallback pour les hors-sujet
✅ Instruisez le LLM à dire « Je n'ai pas cette information dans mes documents » plutôt que d'inventer.
Conclusion : le RAG est le socle de l'IA fiable
Le RAG n'est pas une mode. C'est le pattern architectural dominant pour toute application IA qui touche à des données d'entreprise.
Gartner prédit que d'ici fin 2025, plus de 80% des applications d'IA d'entreprise utiliseront le RAG sous une forme ou une autre. Ce n'est plus une question de "si", mais de "comment bien le faire".
La prochaine fois qu'un chatbot vous donne une réponse parfaitement fausse, demandez-vous :
"Est-ce qu'il utilise le RAG ?" — La réponse sera probablement non. 🎯